
Posted on May 7, 2015
When the “Quantified Self” meets Medical Reality
So, there was a bit of a twitter row a few weeks ago when Mark Cuban and a number of healthcare people got in a debate about the frequency of lab testing.  Mark posted a tweet that started, according to Forbes: “A digital firestorm“.  I think the original tweets were deleted, but the Forbes article says they were:
1)If you can afford to have your blood tested for everything available, do it quarterly so you have a baseline of your own personal health
— Mark Cuban (@mcuban) April 1, 2015
2) create your own personal health profile and history.It will help you and create a base of knowledge for your children,their children, etc
— Mark Cuban (@mcuban) April 1, 2015
3) a big failing of medicine = we wait till we are sick to have our blood tested and compare the results to “comparable demographicsâ€
I first heard about this from Aaron Carroll (@aaronecarroll) on The Incidental Economist (TIE) blog.  I’m a regular follower of the blog, and I have a lot of respect for Aaron; his writing is well researched and delivered; he writes for a few sites and it’s all great — here’s his most recent piece on wasting research on settled science, which is spot on, as most of his writing is.  Anyway, the blog (TIE) hits that sweet spot where I agree almost always, but occasionally see a different perspective.  The primary reason for this is that what I do (all things Data) is central to medical research (Dr. Carroll’s main blog focus), but also completely removed from it since I don’t typically use research-level medical data.
I’d pretty much resolved to stay out of this discussion (beyond what I did on twitter), but Aaron posted a video on the topic yesterday, refreshing it in my mind, and this particular topic crosses several personal sweet spots, so I thought I’d chime in.  I think my blog has like 5 readers, so it shouldn’t matter much anyway.
It’s an interesting discussion to me because I’m in the position of agreeing with both sides (although I have less exposure to Mark Cuban than I do to TIE), and just believing that they’re misunderstanding one another’s perspective.  Let me break down what I see as the disconnect.
First, there is a growing assortment of people who are big into the “Quantified Self” thing. Â These are people who measure everything, all the time. Â Caloric intake, steps walked, heart rate, and much more. Â Technology has made this data collection possible only a handful of years since the best we could hope for was standing on a scale every morning and keeping a handwritten paper log. Â Reasonably affordable GPS watches can help you with stride length, and 24/7 heart rate monitors can be worn comfortably on your wrist.
I take Mark Cuban’s tweets as an extension of this.  My view is that I just want the data, so that I can analyze it myself, and learn from it, in the same way I do about exercise and calories.  From this growing movement’s online profile, I’m pretty sure I’m not alone in this interpretation.
The healthcare opposition is straightforward:  more testing leads to a litany of problems, starting with false positives.  Aaron Carroll is leading the charge for this side.  Research and background is strong here, and he’s absolutely correct.  Breast Cancer is a common discussion point:  breastscreeningfacts.org has this dizzying infographic, while Vox recently published similar results as a reply to Taylor Swift coming out for more cancer screening.  The former chart is here:
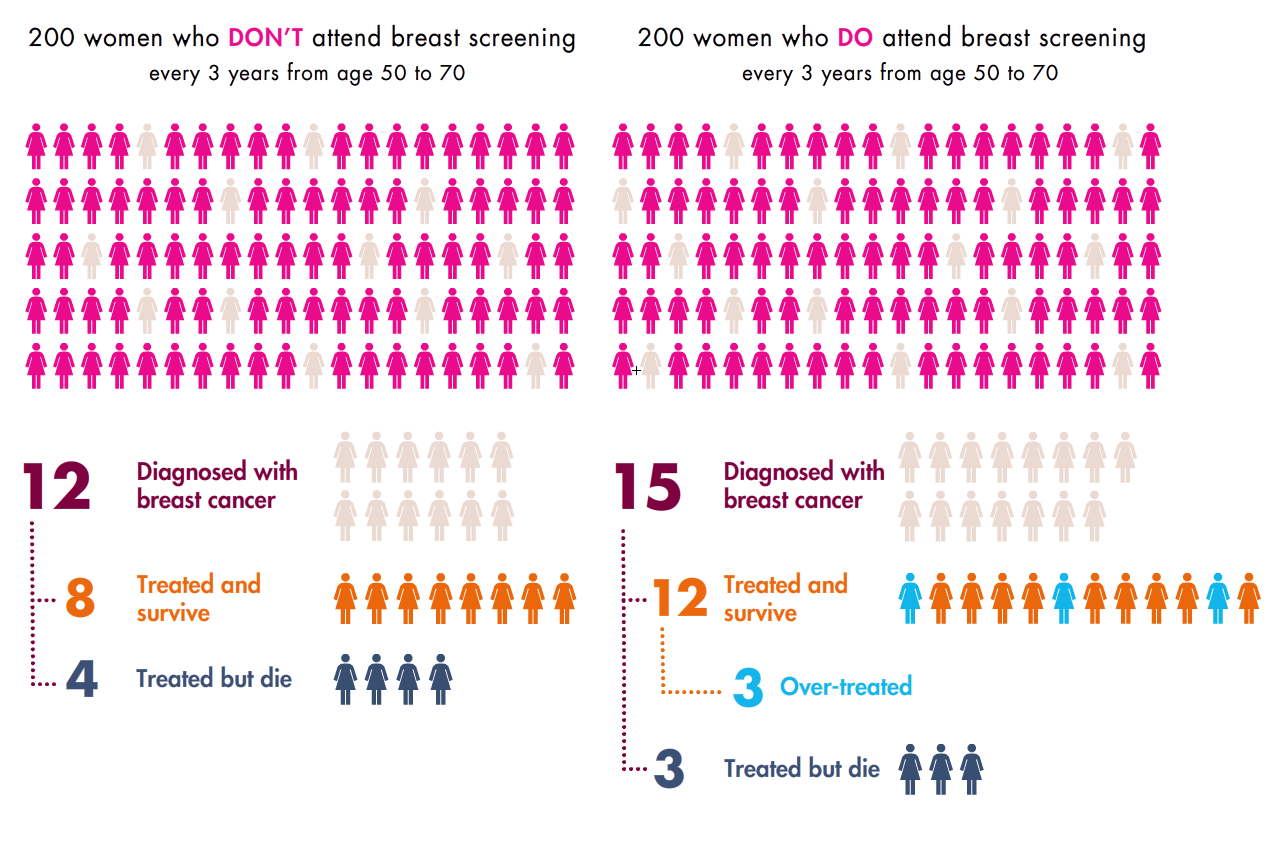
And these guys are right. Â There’s every indication that over-screening is wasting healthcare dollars, subjecting patients to unnecessary and possibly harmful additional tests, and barely (if at all) doing any good for actual outcomes.
HOWEVER, I still don’t see these as polar opposite arguments.  Taylor Swift, coming out specifically for breast cancer screening is what these charts oppose.  Taking lots of additional personal measurements of easy-to-gather metrics, such as Glucose, Cholesterol, White Blood Cell, or whatever, is not the same as “screening”.  Mark Cuban posted this tweet on the topic:
“there is a HUGE difference between data collection and diagnosis. No reason to go to doctor to get blood work” (tweet to @charlesornstein from @mcuban)
And I agree. Â I think we’re talking about two different things, here’s a flowchart (I advocate flow charts for these sorts of discussions):

At the top is what I’m talking about.  Get lab results.  Get them regularly.  Write them down.  Can you afford quarterly?  Great!  Can you afford daily?! Even better!  I predict that prices will drop and personal data tracking will become more readily available in many more quantifiable areas.  That’s great; that’s what we’re going for.  But the “we” here is the personal analytics folks.  I can be accused of being a data hoarder sometimes, and that’s not unreasonable, but that’s a result of being in a world where data mining and “big data”* are really driving a lot of new insight.
The problem, and the medical folks are quick to point this out, is that it’s human nature to interpret results.  They argue that the bottom scenario is inescapable — where an irregular measurement from some lab result must be followed up, quickly, with further testing.  They seem to be arguing that this is due to a combination of factors, many human, many procedural within medicine.  That is, first, anyone looking at their own data and finding an anomaly will naturally want more information, and so seek out additional tests.  They’ll likely get to a doctor who, ethically enjoined to treat a patient that comes to them with a concern and an abnormal test (even a mild one), will provide more tests.
I’m recommending a middle ground: Â don’t recommend frequent blood tests for everyone, but understand, cooperate, and do not be dismissive with the perspective of people who prefer, and can afford, and can behave rationally, with the additional data.
I think there are plenty of people who can learn from far more frequent measurements, and who will actually get MORE peace of mind out of it rather than less. Â I think I’m one of those people. Â I like knowing my cholesterol and glucose numbers; I had to have a conversation with my doctor the first time I did blood tests, years ago, to understand the results, but there wasn’t much to it. Â Some were normal, some were great, some were borderline. Â Having a chart of those over time, and frequently, would be a huge addition to my personal understanding of how my body works. Â I promise not to freak out if some number spikes on one day and then goes normal again — rather than freak out, I’d assume it was a measurement error, or more likely have learned something about how much cheating on a glucose fast really matters when Krispy Kremes are involved.
But individualized medicine isn’t prepared for this.  Most people aren’t data driven, and aren’t able to be objective about this sort of thing with their health.  If you’re one of those people, yes, keep going to the doctor the way you usually do.
[Note: Â this is where I really start to ramble]
Let’s look at Aaron’s recent video. Â You should go watch it. Â I’ll be here. Â He gives good examples of this happening.
Welcome back.
Aaron nicely laid out some points, and has a lot of good quotes, so let’s look at them:
1. “Too many people think that tests are binary things. Â They’re not.”
Absolutely!  But so what?  In fact, this is MORE reason to test more, and learn the intricacies of the data.  He says “if someone got this value with no other data I’d have no idea what to do with it.  You have to interpret it in context.”  But a repeated baseline is context.  The very point is to build context.  I am not recommending interpreting the data at all at an individual test level.  The more data you have, the more context you have when you need it.  Outlier detection, which is what medical tests boil down to, is a big deal in data mining, and it’s difficult to do with few data points.
2. “When lab tests pick up something that isn’t real, it’s a false positive”
Two things from point one matter here.  First, we agreed that tests aren’t binary.  “Positive” and “Negative” are binary, so healthcare is the one treating non-binary data in a binary way.  That’s the opposite of what I’d recommend, so while it sounds like we agree, the problem isn’t with extra testing, it’s with over-interpretation.
TO REITERATE HOWEVER: Are you going to freak out every time a test goes slightly above borderline?  THEN THIS ISN’T FOR YOU.
Dr. Carroll talks about specificity and reliability of tests — he’s absolutely right about all of this information, but again his context is about diagnosing, not just data collection.  Different points of view entirely.
3. “What do you do with the abnormal value?”
Store it.  Save it for later.  Same with normal values.  We expect that test results from otherwise uninteresting days are normal.  Store a few of them up, then consider them all, together, when you visit your doctor.  See, one problem is that doctors don’t get to see their patients very frequently (and there’s not enough doctor time or money to go around to change this even if we wanted to).  The entire system of blood and other testing is based around the premise that if something is wrong, you’ve got a small window to catch it — like an annual physical that most people only take every couple of years.  Doctors are geared up for that kind of thinking, and it’s a more delicate balance if that’s your reality.
If you start from the assumption that you’ll have one blood test per year then you have no choice but to get worried if your number is out of some boundaries set with a very wide cohort. Â We have to compare test results for YOU against all the other people in your age and race and gender brackets, which is millions of people, because that’s all we have.
Charles Ornstein, who got involved online, takes this on a bit.
I think there’s a misunderstanding that diagnosis is some super clear black-white kind of distinction, when in fact there are 1,000 shades of gray in between. The time you get into that gray is when you’re dealing with people who feel fine and have some detectable abnormality. That’s how we get into it in cancer screening. We’re looking for very early signs of disease. There’s going to be great pressure to react to those abnormalities.
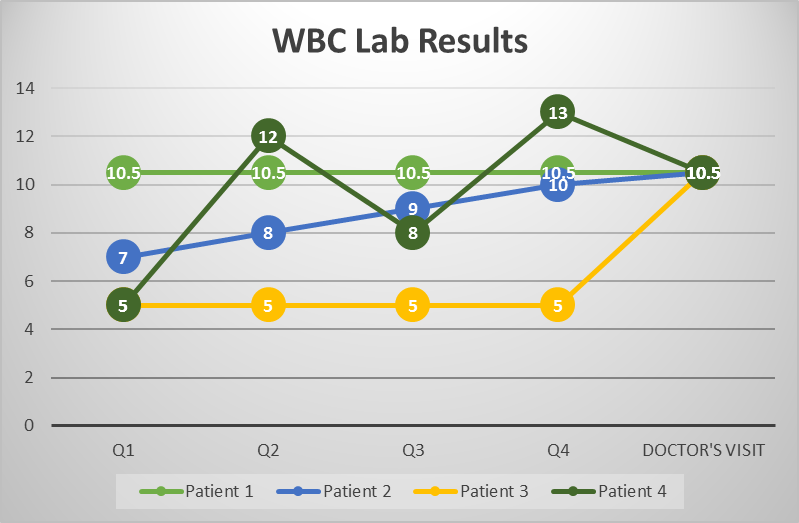
Where is the problem there?  I see several logical issues.  First, and again, we say something isn’t black and white, but that there’s a “detectable abnormality”.  No, that’s wrong.  There’s a statistical deviation.  In some cases it’s very large, in some cases very small.  Again, I don’t see how more data wouldn’t help clarify.  Cancer detection is tough, and one technique used is to wait and retest.  If you get your first PSA test (a prostate cancer indicator) at age 50, and it’s borderline, what are we comparing it against?  What if you had monthly tests for 10 years personalized to you but didn’t look at them until 50?  There is NO WAY that would not be more informative.  Look at this completely fictional chart:

Would you treat these patients differently, if you only saw them at the one Doctor’s Visit?
If four patients came to a doctor with a WBC (White Blood Cell test) reading of 10.5, and the same (if any) symptoms, they’d be treated the same.  But what if each of those four patients brought different histories with the same test?  How can this not be more informative?  The fact that doctors may not know how to use the information, because the research hasn’t been done, doesn’t mean it is not informative to the open discussion between patient and doctor.  If I were Patient 1, with a level reading every quarter, I’d probably feel comfortable not having additional tests.  Patient 3, with a recent spike, would almost certainly what some treatment.  Patient 2, with the constantly increasing results would probably ask more penetrating questions, and Patient 4 is probably someone the doctor should ask more history questions of (i.e. did you feel feverish when you took the last blood test?).  In each case I’m not saying that the chances of over or under diagnosing are necessarily better, but the discussion could be so much richer at the one doctor’s visit with a history.
I asked something similar of Dr. Carroll directly (he was kind enough to have a bit of twitter banter with me during these conversations).  In his blog posts he says that if you have a WBC just out of range, what does that mean?  Without context — secondary symptoms — it may mean nothing, or it may still be the result of something, we don’t know, and that’s the problem (remember, tests aren’t yes/no binary answers).  OK, so I asked, wouldn’t it be MORE helpful to know that a person had one value that was significantly different than that person’s individual baseline?  A 10.5 when the person had 5s for months?
He answered that, no, and he talked to other doctors and they wouldn’t treat that information any differently.
I was surprised. Â But when I thought about it, that surprise went away, and this is why:
_I_ AM a data scientist.  Most doctors are NOT.  They have to deal with individual patients with techniques they’ve developed over years (centuries as a profession) garnered from other patients.
I could go on dissecting other people’s quotes on this topic for ages. Â It always boils down to one thing: Â Doctors have to deal with treating individual patients, and their experience — correctly — makes them interpret a request for more tests as a request for more action, diagnosis, and screening, while a new breed of quantified-self patient is emerging, some of whom really want the data for their own sake.
Most doctors in this argument at some point say that they believe in working with a patient to find the correct course of treatment (or non-treatment) for them.  I say we embrace this, but admit that some patients would fall into a category of frequent data collection.
Pingback: On Repeated Medical “testing” | chiplynch.com